
InnoDB implements multi-version concurrency control (MVCC), meaning that different users will see different versions of the data they are interacting with (sometimes called snapshots, which is a bit of a misleading term). This is done in order to allow users to see a consistent view of the system without expensive and performance-constraining locking which would limit concurrency. (This is where the “concurrency control” part of the term comes from; one alternative is locking everything the user may need.) Undo logging and InnoDB’s “history” system are the mechanisms that underly its implementation of MVCC, but the way this works is generally very poorly understood.
InnoDB keeps a copy of everything that is changed
The key thing to know in InnoDB’s implementation of MVCC is that when a record is modified, the current (“old”) version of the data being modified is first stashed away as an “undo record” in an “undo log”. It’s called an undo log because it contains the information necessary to undo the change made by the user, reverting the record to its previous version.
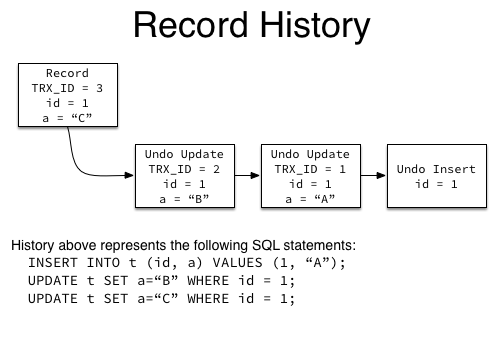
Every record contains a reference to its most recent undo record, called a rollback pointer or ROLL_PTR, and every undo record contains a reference to its previous undo record (except for an initial record insert, which can be undone by simply deleting the record), forming a chain of all previous versions of a record. In this way, any previous version of a record can be easily constructed, as long as the the undo records (the “history”) still exist in the undo logs.
Transactions always operate on the “live” data — there are no private copies
Any transaction1, no matter how small or temporary it may be, is always operating on the database. As records are added, modified, and deleted, this is done in the very same index structure that all other transactions and users are actively using. Although the data for these in-flight transactions may not be visible to other transactions (depending on their transaction isolation level), the effects—particularly the performance costs—associated with those modifications are immediately visible.
When reading an index, a transaction uses a “read view”, which controls what version of records a transaction is allowed to see. While reading records in the index, any recently modified record (modified by a transaction whose ID is newer than the reading transaction’s read view would allow it to see) must first be reverted to an old-enough version. (And this may cause the record to not be visible at all.)
When a transaction updates a record, without yet committing, all other transactions using transaction isolation are immediately impacted by having to revert the version of that record to an older version (that they are allowed to see) every time they encounter the record in a read.
What about transaction isolation levels?
There are three transaction isolation levels of interest for undo logging, history, and multi-versioning:
- READ UNCOMMITTED — Also known as “dirty read”, because it literally always uses the newest data in the index without regard to transaction isolation at all, potentially reading data which isn’t currently (and may never be) committed. Even within a single statement, transactional inconsistencies may be seen from one record to the next, because no record is ever reverted to a previous version during a read.
- READ COMMITTED — A new read view is used for each statement, based on the current maximum committed transaction ID at statement start. Records read or returned within the statement will still be consistent with each other, but from statement to statement the user will see new data.
- REPEATABLE READ — The default for MySQL/InnoDB. A read view is created at transaction start, and that read view is used for all statements within the transaction, allowing for a consistent view of the database from statement to statement. That is, reads of data are “repeatable” within the transaction.
(Additionally there is one more transaction isolation level supported by MySQL/InnoDB, called SERIALIZABLE, but it is primarily a difference in locking, not transaction visibility, compared to REPEATABLE READ.)
In the normal course of accessing an index, some small number of records will need to be reverted to a previous version in order to satisfy the transaction isolation requirements imposed by the system. This has a cost, but as long as the read view of the transaction is fairly new, most records will not require reversion, and there is very little performance cost to doing this.
Long-running transactions and queries
It is common and mostly unsubstantiated wisdom that long-running transactions are “bad” in MySQL — but why is that? There are two reasons that long-running transactions can cause problems for MySQL:
- Extremely old read views. A long-running transaction (especially in the default REPEATABLE READ isolation level) will have an old read view. In a write-heavy database this may require reverting the version of very many rows to very old versions. This will slow down the transaction itself and in the worst case may mean that very long-running queries in a write-heavy database can never actually complete; the longer they run the more expensive their reads get. They can spiral into performance death eventually.
- Delaying purge. Because a long-running transaction has an old (potentially very old) read view, purging of undo logs (history) for the entire system will be stalled until the transaction completes. This can cause the total size of the undo logs to grow (rather than re-using the same space over and over as it normally would), causing the system tablespace (ibdata1) to grow—and of course due to other limitations, it can’t be shrunk later.
If a very long-running transaction (or query) is needed, it’s well worth considering whether it could use dirty reads in READ UNCOMMITTED isolation level in order to avoid these problems.
Deleting isn’t really deleting
Whenever a record is deleted, other transactions may still need to see the record as it existed, due to transaction isolation. If, upon delete, the record was immediately removed from the index, other transactions wouldn’t be able to find it, and thus would also not be able to find its reference to the previous record version they may need. (Keep in mind that any number of transactions may see the record in any number of versions, so five different transactions may see up to five separate versions of the record.) In order to handle this, DELETE doesn’t actually delete anything: instead it delete marks the record, flipping a “deleted” flag on.
Global history and purge operations
In addition to every record having a reference to its previous version, there is also a global view of the history of the entire database, called the “history list”. As each transaction is committed, its history is linked into this global history list in transaction serialization (commit) order. The history list is used primarily for cleaning up after a transaction, once no existing read view still needs its history (all other transactions have completed).
In the background, InnoDB runs a continuous “purge” process which is responsible for two things:
- Actually deleting delete-marked records2, if the current version of the record in the index at the time of purge is still delete-marked and bears the same transaction ID. (That is, the record hasn’t been re-inserted.)
- Freeing undo log pages and unlinking them from the global history list to make them available for re-use.
InnoDB exposes the total amount of history present in the system as a “History list length”, which can be seen in SHOW ENGINE INNODB STATUS. This is the count of all database modifications present in the undo logs, in units of undo logs (which may contain a single record modification or many).
What’s next?
Next, the physical structure of the undo logs, undo records, and history will be examined.
—
1 Note that InnoDB does not start a transaction internally when a BEGIN or START TRANSACTION is issued; this happens only after the first read, or immediately if START TRANSACTION WITH CONSISTENT SNAPSHOT is executed.
2 Of course actually deleting the record still doesn’t actually delete it — it just links the record into a “garbage” list, where record space may be reused. However nothing is guaranteed to be really removed from a page until the page is re-organized.
