[This post refers to innodb_ruby version 0.9.11 as of October 2, 2014.]
Many DBAs know that building indexes in “random” order (or really any order that greatly differs from ordered by key) can be much less efficient. However, it’s often hard to really understand why that is. With the “-illustrate” visualization modes available in innodb_ruby, it’s possible to quite easily visualize the structure of indexes. The space-lsn-age-illustrate mode to innodb_space allows visualization of all pages in a space file by “LSN age”, generating something like a heatmap of the space file based on how recently each page was modified.
(Note that a small Ruby script generate_data_simple.rb was used to generate the test tables used below. You’ll also want to have a reasonable monospace font supporting Unicode block characters correctly, for which I’d heartily recommend Adobe’s Source Code Pro.)
Building an index by insertion in key order
Inserting rows into an index in key order is much more efficient primarily for two reasons:
- Pages can be filled completely, and the database (with sufficient optimizations present) can detect the “bulk loading” behavior and efficiently split pages by creating new, empty pages, rather than splitting pages in half.
- Only the “edge” of the index is being written to; once a page has filled it will not be revisited. This can make the buffer pool, which caches database pages, much more effective.
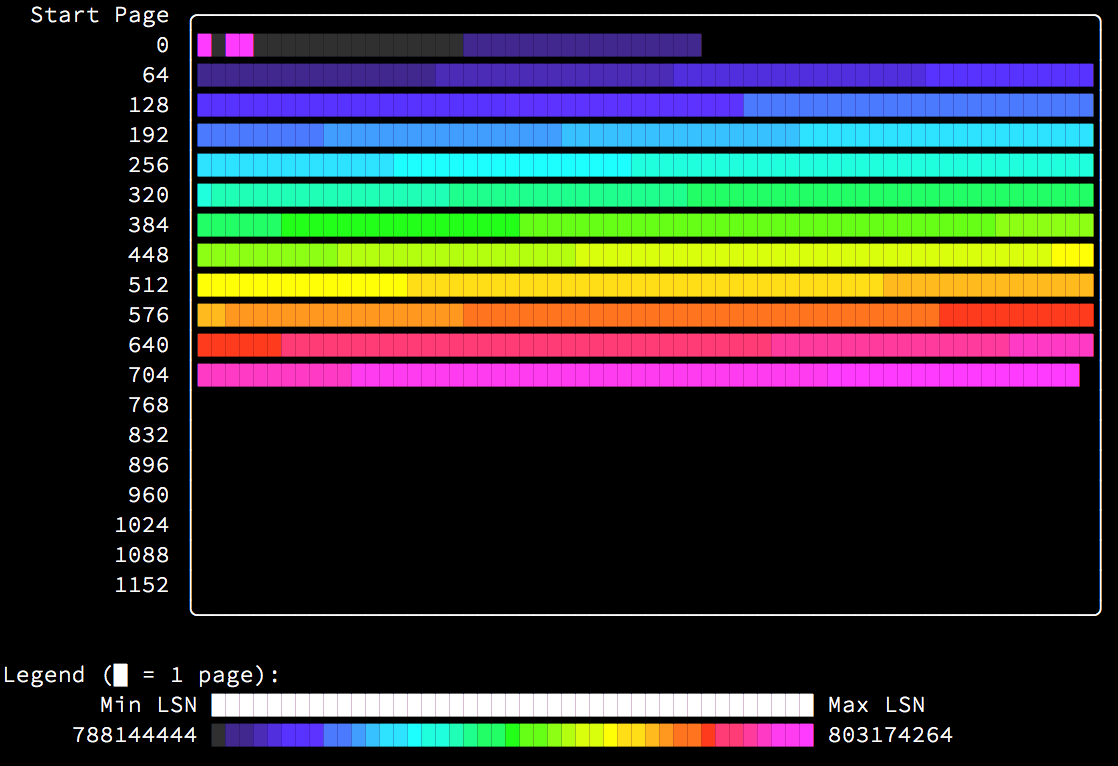
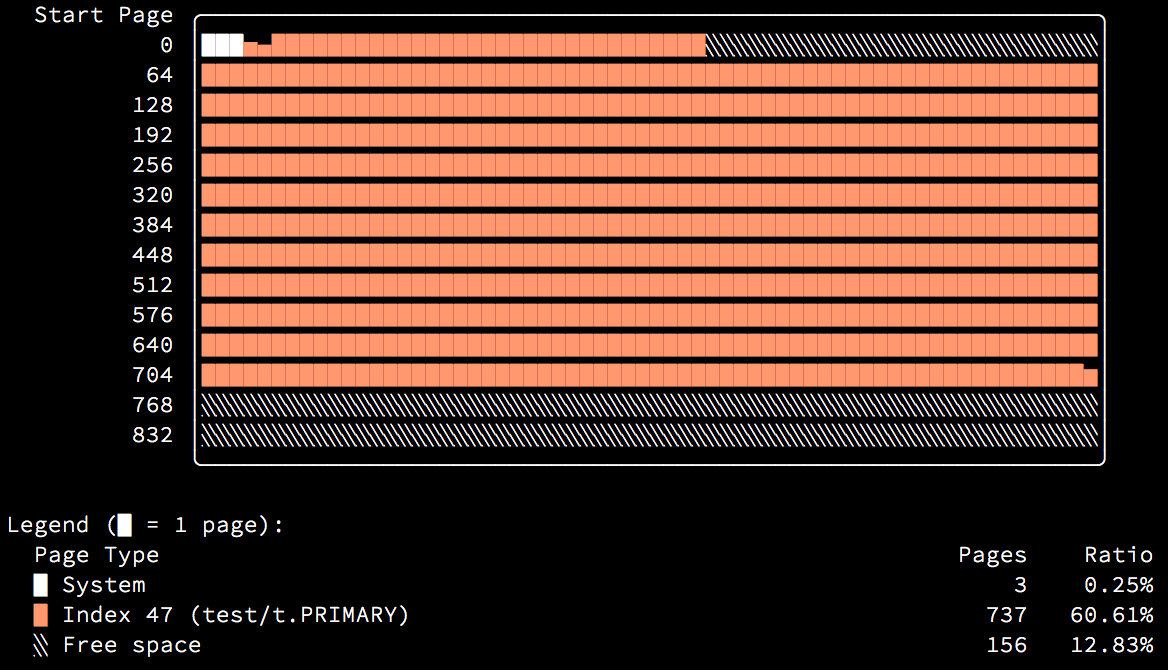
Here’s an example of a table with only a PRIMARY KEY clustered index, built by inserting rows in key order:
$ innodb_space -s ibdata1 -T test/t space-lsn-age-illustrate

As you can see in the above image, the index pages are written to in nearly perfect order as they are allocated from the beginning of the file towards the end.
The first extent (the first line of the image) is allocated as a fragment extent, and contains single pages allocated for different purposes. You can clearly see the tablespace bookkeeping pages, FSP_HDR at page 0 and INODE at page 2, immediately followed by the root index page at page 3, all very recently modified. Following that are 32 individually allocated “fragment” pages which were allocated first in the index before it switched to allocating full extents. Then the index pages progress perfectly until the end of the used space.
Also note the LSN age histogram (printed in white above the colored legend at the bottom) shows all buckets equally filled.
Building an index by insertion in random order
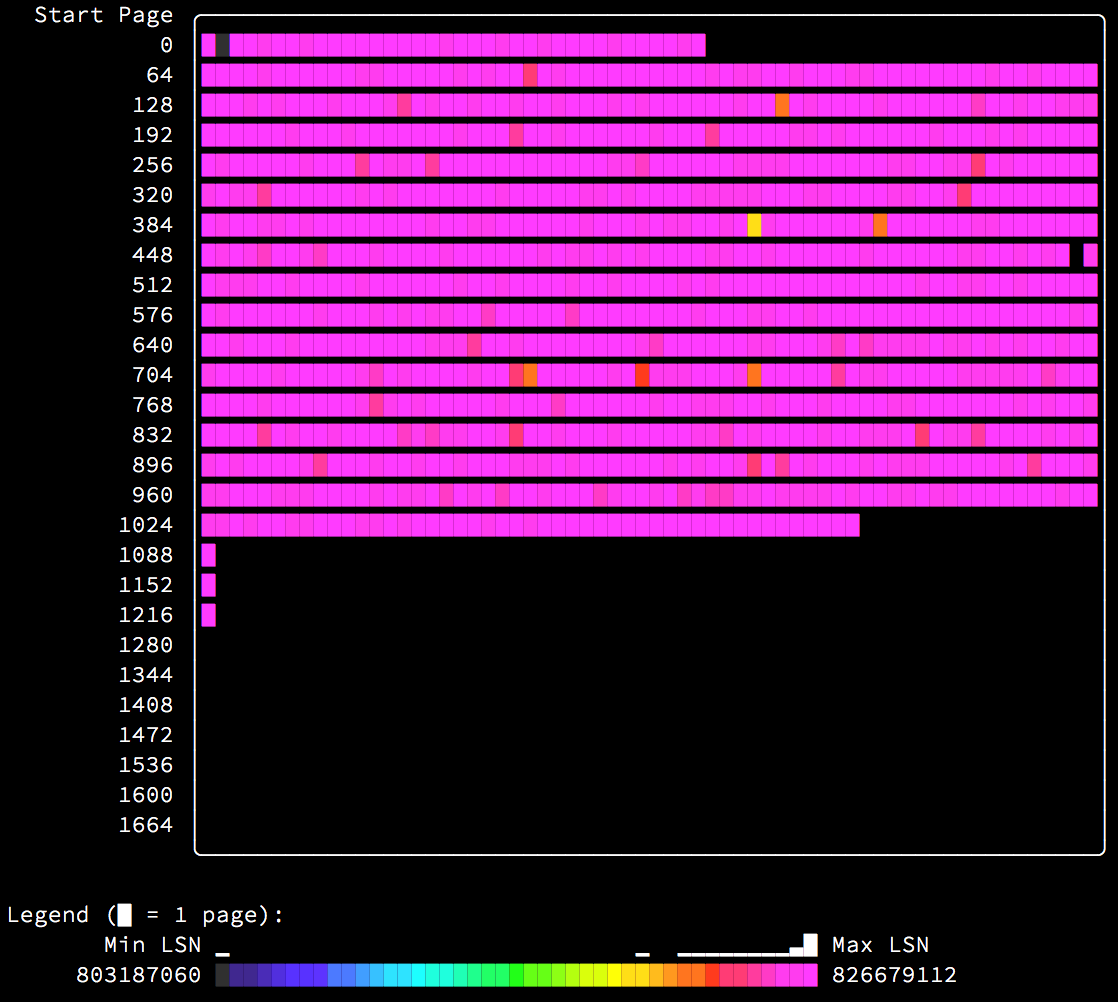
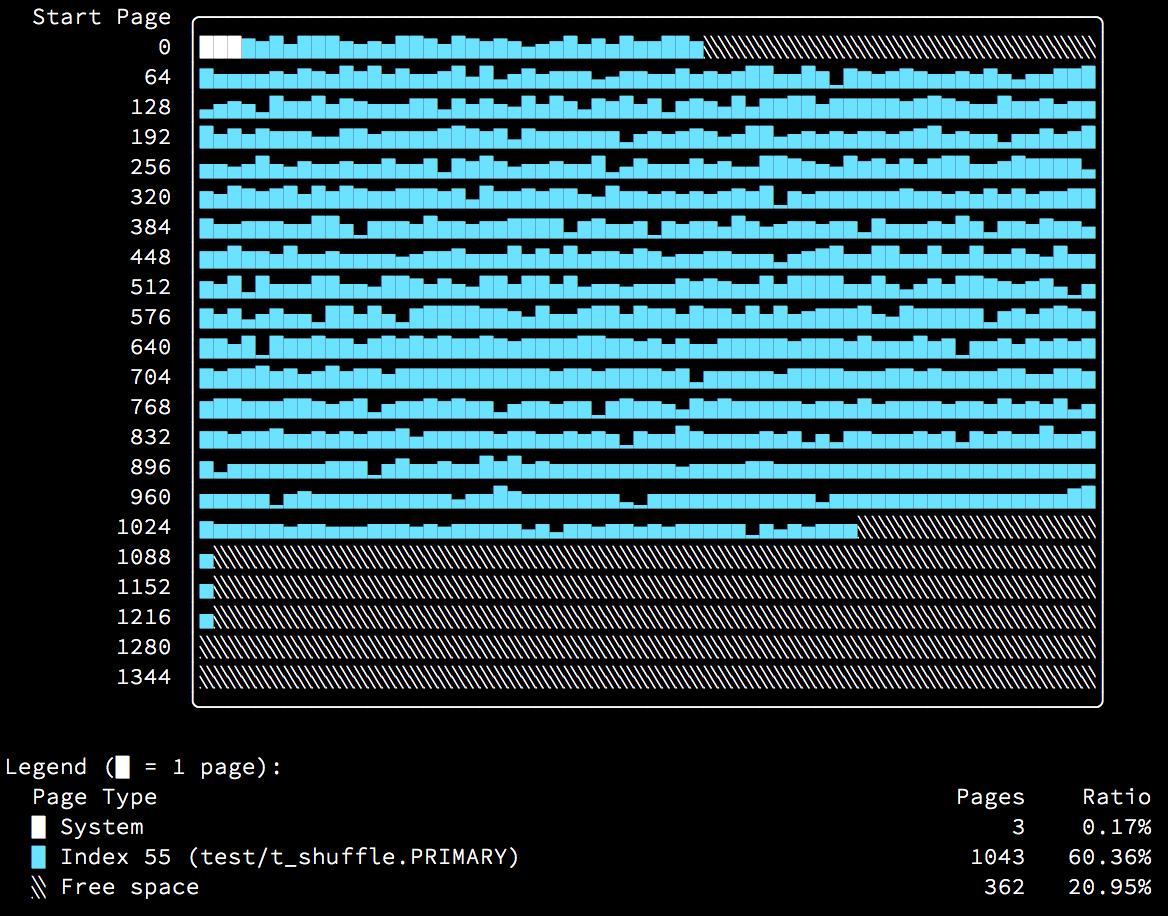
Looking at an index built by insertion in key order was reassuring. What if it is built in random order instead? The result is perhaps a bit surprising:
$ innodb_space -s ibdata1 -T test/t_shuffle space-lsn-age-illustrate

Because the rows were inserted in completely random order, every page has an equal chance for insertion. This means in practice that every page is very recently modified, and this is clearly visible by the entire heatmap being purple. What this also means is that the entire table must be continually present in the buffer pool, and if it doesn’t fit, performance will suffer greatly. This is the main reason that performance of insertion in random order is terrible.
Additionally, you can see a few misbehaviors of InnoDB: Note the extents starting at page 1088, 1152, and 1216. Why do you think they look like that? Let me know your ideas in the comments.
Building a primary and secondary index in primary key order
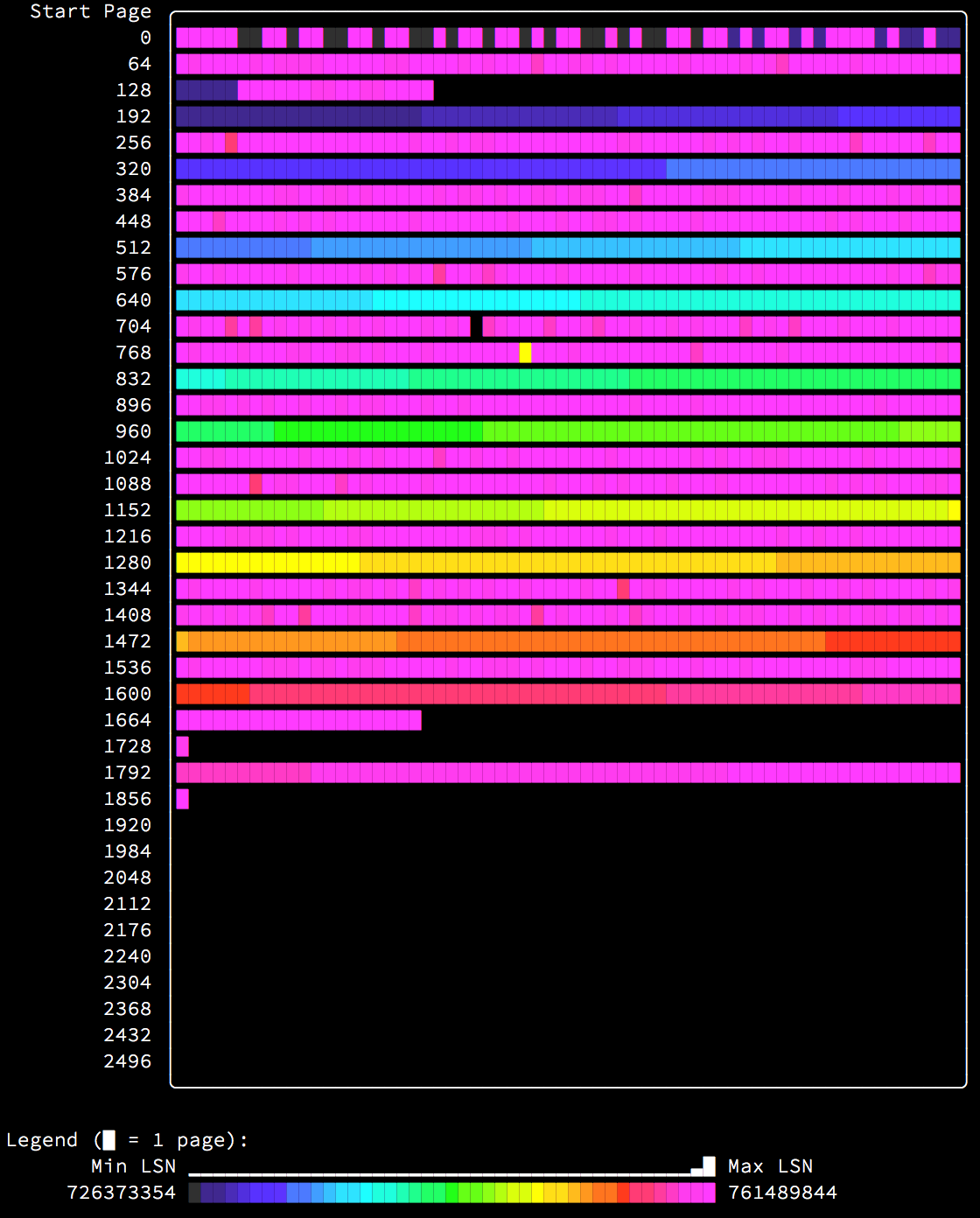
What if you have multiple indexes? Looking at a very simple and typical case, inserting data in key order by the primary key, while a secondary index exists:
$ innodb_space -s ibdata1 -T test/t_index_before space-lsn-age-illustrate

Notice that this looks like the previous cases perfectly interleaved together, because it is exactly that. Since the primary key and secondary index contain completely different data, insertion is ordered by the primary key, but completely mis-ordered by the secondary index, resulting in the secondary index being built inefficiently.
Adding a secondary index to an existing table
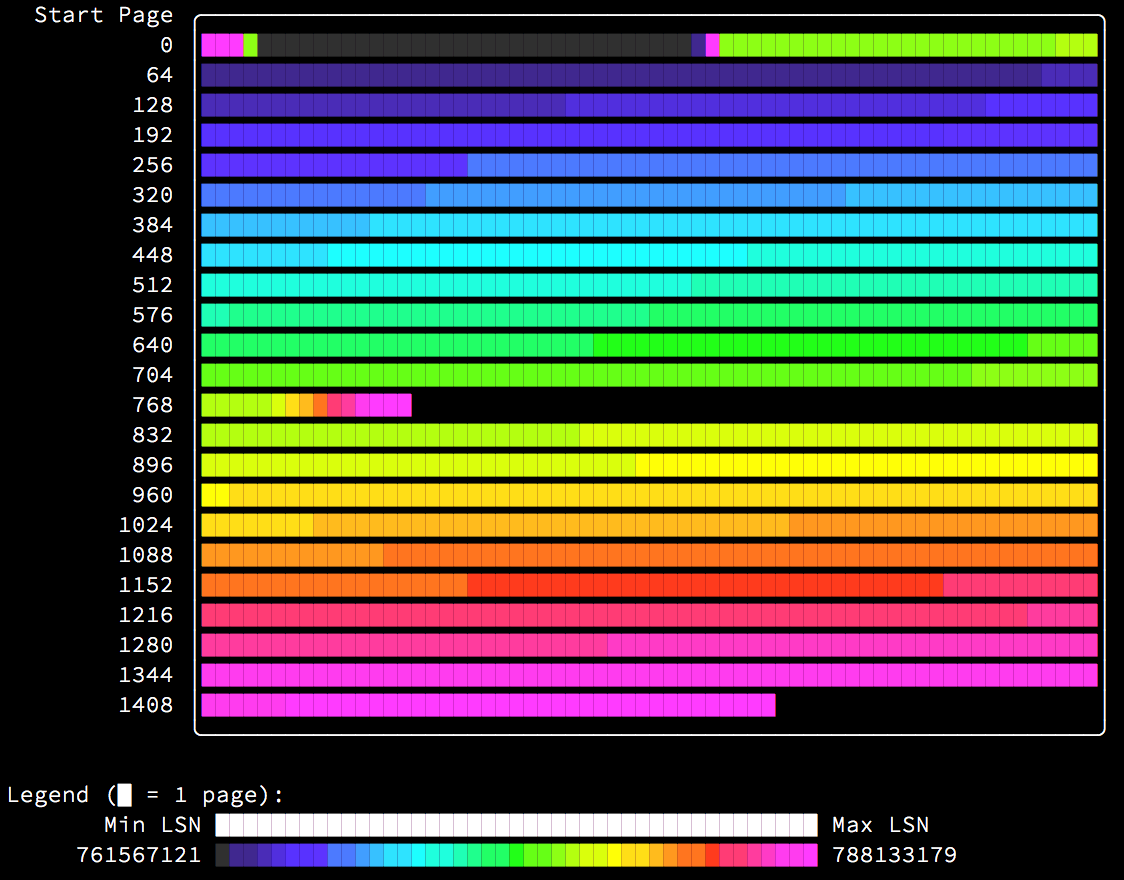
The obvious answer then to the previous problem is to add the index after the data has been loaded, and this does in fact result in the expected outcome:
$ innodb_space -s ibdata1 -T test/t_index_after space-lsn-age-illustrate

When the index is built on the existing table (via ALTER TABLE ... ADD INDEX), it is built by scanning and sorting the data before insertion into the index, resulting in an optimal (and very fast) index build.
Visualizing page fill rate
While the above illustrations show how recently each page was modified during the index build, it’s also possible to use space-extents-illustrate to visualize how full each page is. The key-ordered index looks like this:
$ innodb_space -s ibdata1 -T test/t space-extents-illustrate

Compared to the random-ordered index:
$ innodb_space -s ibdata1 -T test/t_shuffle space-extents-illustrate

The random-ordered insertion caused pages to be split more frequently, and in some cases to be severely under-filled, causing a very poor page fill rate on average.
Those of you who are particularly observant will have noticed that the index illustrations in the first pictures above showed that the ordered-insertion index is significantly smaller than the random one. You can see here that the random-insertion index is 41% larger at 1043 pages compared to just 737 pages for the ordered-insertion index. Additionally, 206 more pages are left unused, making the actual disk space usage 57% larger.